Create a Web App
Table of Contents
An Introduction
Welcome to the StartHacking web track! The goal of section is to provide some background information on how the Internet works, as well as provide the conceptual and technical skills needed to start developing web sites and web appliactions!
How does the Internet work?
Since the Internet has become a backbone of our modern-day lives, a good understanding is needed to become a great Web Developer, and use this tool most effectively.
This section will explain the underlying infrastructure and technologies that make the Internet work; it won’t provide a very detailed explanation, and resources will be provided at the end for those who wish to learn more. Any comments, questions, suggestions, etc are welcome! Check out the contributing section of StartHacking.org!
Let’s do a deep dive of exactly what happens, from when you type https://google.com in your browser to the moment it shows up on your screen.
Internet Addressing
When the Internet was first founded, it nothing more than a network of computers for academic purposes; there was no way to go to google.com, because there was no concept of a named website, or a domain. Computers were connected to each other solely on the basis of an address of the form xxx.xxx.xxx.xxx, where xxx is a number from 0 - 255.
More recently, these addresses can also take a form of xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx, where x is a hexadecimal number between 0 and 15! This hexadecimal notation, commonly referred to as IPv6, was developed in 2012 after we began running out of simpler IP addresses!
This address is known as an IP address, and this is what our computer systems still use. When you go to a domain, it looks up the underlying IP address, using the Domain Name System (DNS), and directs you to there. For example, Google’s IP address for my region is 216.58.219.46. Google actually has different servers for each region for the purpose of handling demand, so you may be seeing another IP than is listed here. Additionally, it’s important to note that IP addresses are unique; no two servers can share the same IP address! Can you see why this could be a problem?
Check it out! Open Terminal if you’re on a Mac (instructions), or Command Prompt if you’re on a PC (instructions). Type in
ping google.comand see Google’s IP address for yourself!
Domain Name System
Can you imagine if you had to memorize an IP address for every website you wanted to go to? That’d be incredibly troublesome; facebook wouldn’t be facebook.com, it’d be 19.27.5.20. It’s obvious that the human mind isn’t able to memorize arbitrary sets of numbers as well as it is able to remember meaningful names. To fill this need, the Domain Name System (DNS) was invented.
The Domain Name System functions as almost as a digital equivlant of a yellow telephone book; it provides the functionality to lookup a domain name and get an equivalent numerical IP address. Since DNS is a distributed data store, no one server can contain the entire database; this is for safety as well as security: can you imagine if the DNS went down, or someone was able to hack into it?
Therefore, many different servers hosts a small portion of the database, and they all use a common set of software to communicate between each other. We call these computers DNS servers. Since all of these DNS servers can communicate between one another, if a DNS server does not contain the domain name requested, it simply redirects it to the next server which may contain the desired information. This way, you’re continually redirected down the hierachy until you get to the domain name you request (as in the figure below). Neat, huh?
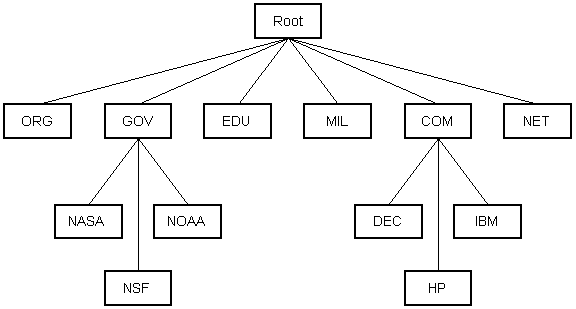
Diagram sourced from stanford.edu.
Check it out! What DNS server are you using? Type in
nslookup facebook.comin either Command Prompt (Windows), or Terminal (Mac).
HTTP and the World Wide Web
So what really happens when you type in google.com into your browser? Once the Domain Name System translates the domain name into an IP address, your request is sent to the server to decode. This is done over a protocol called the HyperText Transfer Protocol, or HTTP. This is why most URLs are prefixed with http://facebook.com. When you add the http://, you’re telling your web browser to use a specific protocol.
To provide some background, hypertext was called structured text that uses connections (links, or URLs) between servers containing text. Therefore, the hypertext transfer protocol specifies how to exchange and transfer this hypertext between servers. HTTP functions as a request-response protocol; that means that each response must be triggered by a corresponding request. To put this into practice, let’s imagine our server requests a particular file, silverman.jpg. Our server could see this request, and will respond with a status code and a message payload. In this case, it will respond with HTTP 200 OK, meaning that the request was successful, and a copy of silverman.jpg.
It’s important to understand that HTTP is a connectionless, text-based protocol. After the request is serviced, the connection between your web browser and a server is disconnected; a new connection must be made for each request. This is why Web Developers attempt to minimize latency, or the time to initialize a new connection, by bundling smaller requests for information together into one larger request.
Try it out! Simulate an HTTP request on your own.
Now that you know how HTTP works, it might be useful to simulate how these transactions work on your own. In this exercise, we’ll use telnet, a text-communication tool between servers, to simulate an HTTP request.
Note: if you’re on Windows, you’ll have to enable telnet using these instructions. If you’re on a Mac, please follow our Mac Setup Instructions, and then run
brew install telnetin the terminal.
Begin by opening Terminal or Command Prompt. Type telnet hackmit.org 80.
What does the
80mean? Each web server runs on a particular port; think of ports as the house number. You may be on a particular street, meaning a particular IP address, but the port will tell you what door to knock on! HTTP servers typically run on Port 80, HTTPS servers typically run on Port 443, DNS servers typically run on Port 53, and email servers run on Port 25! This way, you can run multiple services from one computer. Neat, huh?
When the telnet terminal says it’s connected, type in GET / HTTP/1.0, and press enter twice. If you’re on a Windows machine, you may not see what you’re typing, but be rest assured that it is being entered! Congratulations, you just simulated a simple HTTP request to a web server for it’s root page. You should see the corresponding HTML response load into your terminal.
To breakdown this command, you’re asking for a copy of the root file in GET /, and specifying that you’re sending an HTTP v1.0 request with HTTP/1.0.
Wrapping it all together: loading a URL
Congratulations! You’ve now learned about what IP addresses are, how domain names map to IP addresses, how websites are loaded using the HTTP protocol, and you’ve even simulated an HTTP request on your own. Let’s break down what happens when you load a URL into your web browser. Let’s say you just typed in http://google.com into your browser’s URL bar.

A breakdown of a URL into the protocol, host, port, and resource path.
- If the URL contains a domain name, the browser first connects to your computer’s DNS server and retrieves the corresponding IP address for the web server.
- The web browser connects to the web server, and sends an HTTP request for the particular resource. It sends this request to Port 80, unless you specified another port.
- The web server recieves the request and checks for the desired resource. If it exists, the web server sends a status of HTTP 200, and a copy of the resource as text. If the web server cannot locate the resource, it sends an HTTP 404 code, common HTTP-lingo for
Page Not Found. - The web browser recieves the HTTP response, and closes the connection.
- The web browser parses thourgh the resource, and looks for other page elements which may need to be requested. Examples of other page elements may be images, audio, and programming scripts.
- For each element needed, the browser makes additional HTTP connections and requests to the server.
- When the browser has finished loading all resources, it displays the completed webpage to you!
HTML and CSS
HTML stands for Hyper Text Markup Language and will create the structure and content of your web page. CSS stands for Cascading Style Sheets and describes how your HTML elements look on screen. They often work together to create your page and make it pretty. Here are a few tutorials to help you get started with HTML and CSS!
- Codecademy
- w3schools HTML and CSS
- Build a site with Git
Javascript
Javascript can be used to change the content of your website and add different interactive features!
- Javascript basics
- Javscript tutorial for all levels